Hola estimado lector, en esta ocasión voy a dejar un par de apuntes de Pandas y NumPy, en la estadística como caso de estudio ponemos el caso de los puestos de trabajo que he hay en España.
Caso a estudiar
El caso a estudiar será la oferta de puestos de trabajo en España, según diferentes gremios que aparecen en gob.datos.es, de diferentes años, acerca de los trabajos más demandados
Puestos de trabajo totales 2012
Por aquí pongo los puestos del trabajo que hay en total, en España 2012:
import pandas as pd
data=pd.read_csv('20141.csv', sep=';',header=1)
data= data.values
arr_name=[]
arr_tot=[]
for d in data:
if d[0]=='Puestos de trabajo totales' and d[2]==2012 and d[1]!='Total':
arr_name.append(d[1])
str=d[3].replace(".","")
str=str.replace(",", ".")
arr_tot.append(float(str))
import matplotlib.pyplot as plt
## Declaramos valores para el eje y, en este caso son categorias
eje_x = arr_name
## Declaramos valores para el eje x, ahora son los valores
eje_y = arr_tot
## Creamos Gráfica y ponesmos las barras de color verde
plt.barh(eje_x, eje_y, color="green")
plt.ylabel('Numero de Empleados')
plt.xlabel('2012')
plt.title('Puestos de trabajo totales')
plt.show()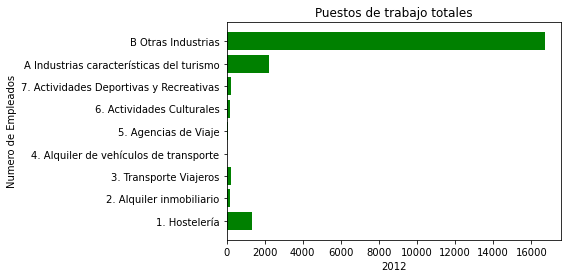
Puestos de trabajo totales 2013
Por aquí pongo los puestos del trabajo que hay en total, en España 2013:
import pandas as pd
data=pd.read_csv('20141.csv', sep=';',header=1)
data= data.values
arr_name=[]
arr_tot=[]
for d in data:
if d[0]=='Puestos de trabajo totales' and d[2]==2013 and d[1]!='Total':
arr_name.append(d[1])
str=d[3].replace(".","")
str=str.replace(",", ".")
arr_tot.append(float(str))
import matplotlib.pyplot as plt
## Declaramos valores para el eje y, en este caso son categorias
eje_x = arr_name
## Declaramos valores para el eje x, ahora son los valores
eje_y = arr_tot
## Creamos Gráfica y ponesmos las barras de color verde
plt.barh(eje_x, eje_y, color="green")
plt.ylabel('Puestos de trabajo totales')
plt.xlabel('2013')
plt.title('Puestos de trabajo totales')
plt.show()
Puestos de trabajo totales 2014
Por aquí pongo los puestos del trabajo que hay en total, en España 2014:
import pandas as pd
data=pd.read_csv('20141.csv', sep=';',header=1)
data= data.values
arr_name=[]
arr_tot=[]
for d in data:
if d[0]=='Puestos de trabajo totales' and d[2]==2014 and d[1]!='Total':
arr_name.append(d[1])
str=d[3].replace(".","")
str=str.replace(",", ".")
arr_tot.append(float(str))
import matplotlib.pyplot as plt
## Declaramos valores para el eje y, en este caso son categorias
eje_x = arr_name
## Declaramos valores para el eje x, ahora son los valores
eje_y = arr_tot
## Creamos Gráfica y ponesmos las barras de color verde
plt.barh(eje_x, eje_y, color="green")
plt.ylabel('Numero de Empleados')
plt.xlabel('2014')
plt.title('Puestos de trabajo totales')
plt.show()
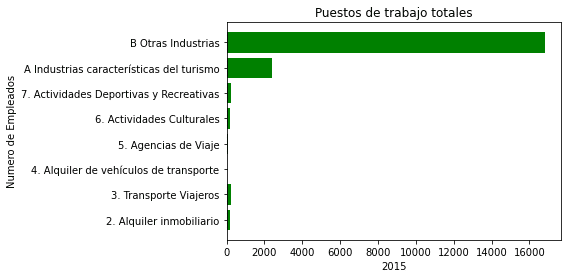
Puestos de trabajo totales 2015
Por aquí pongo los puestos del trabajo que hay en total, en España 2015:
import pandas as pd
data=pd.read_csv('20141.csv', sep=';',header=1)
data= data.values
arr_name=[]
arr_tot=[]
for d in data:
if d[0]=='Puestos de trabajo totales' and d[2]==2015 and d[1]!='Total':
arr_name.append(d[1])
str=d[3].replace(".","")
str=str.replace(",", ".")
arr_tot.append(float(str))
import matplotlib.pyplot as plt
## Declaramos valores para el eje y, en este caso son categorias
eje_x = arr_name
## Declaramos valores para el eje x, ahora son los valores
eje_y = arr_tot
## Creamos Gráfica y ponesmos las barras de color verde
plt.barh(eje_x, eje_y, color="green")
plt.ylabel('Numero de Empleados')
plt.xlabel('2015')
plt.title('Puestos de trabajo totales')
plt.show()